1、MapReduce和Sparkmapreduce与spark的区别的主要区别在于数据处理方式和速度Spark使用内存计算mapreduce与spark的区别,而MapReduce使用硬盘计算mapreduce与spark的区别,因此Spark在处理大数据时通常更快1 数据处理方式 MapReduce和Spark都是大数据处理技术mapreduce与spark的区别,但它们的处理方式存在显著的差异MapReduce是一个批处理系统,它处理数据的方式是通过将大数据集分割成小数据集,然后。
2、而Spark则是一个通用的集群计算框架,它不仅支持MapReduce的处理方式,还提供了更广泛的数据处理功能Spark的核心概念是弹性分布式数据集RDD,它能够在内存中缓存数据,使得迭代算法和实时数据处理变得更加高效Spark不仅能够用于批处理,还可以用于流处理和交互式查询,具有很高的灵活性和性能YARNYet。
3、Spark和MapReduce在计算过程中通常都不可避免的会进行Shuffle,两者至少有一点不同MapReduce在Shuffle时需要花费大量时间进行排序,排序在MapReduce的Shuffle中似乎是不可避免的Spark在Shuffle时则只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时3多进程模型 vs 多线程模型的区别 这俩根本。
4、Spark和MapReduce相比,都有哪些优势一个最明显的优点就是性能的大规模提升通俗一点说,mapreduce与spark的区别我们可以将MapReduce理解为手工作坊式生产,每一个任务都是由作坊独立完成涉及到大规模的生产时,由于每一个作坊都要独立处理原料采购制作存储运输等等环节,需要花费大量的人力计算资源物力能源消耗。
5、其实 Spark 和 Hadoop MapReduce 的重点应用场合有所不同相对于 Hadoop MapReduce 来说,Spark 有点“青出于蓝”的感觉,Spark 是在Hadoop MapReduce 模型上发展起来的,在它的身上我们能明显看到 MapReduce的影子,所有的 Spark 并非从头创新,而是站在了巨人“MapReduce”的肩膀上千秋功罪,留于。

6、MapReduce任务包含Map和Reduce阶段,数据处理完成后,结果写入磁盘,适用于大规模离线计算,但读写数据频繁,耗时且效率低下Spark框架改进了MapReduce模式,提供内存计算模型,支持数据高速缓存和重复使用,加速计算效率Spark采用基于DAG的执行引擎,自动优化计算流程,提高性能Spark任务包含多个Map和Reduce。
7、Hadoop和Spark的异同 差异1 数据处理方式 Hadoop主要基于批处理,处理大规模数据集,适用于离线数据分析Spark则支持批处理流处理和图计算,处理速度更快,适用于实时数据分析2 运行模型 Hadoop依赖集群进行分布式计算,其核心是MapReduce模型而Spark支持多种编程范式,如RDDDataFrame和SQL等。
8、1 分布式存储 Hadoop 分布式文件系统 HDFS一种可扩展的分布式文件系统,用于存储海量数据HBase一种基于 Hadoop 的数据库,用于存储分布式结构化的数据Cassandra一种无模式的分布式数据库,用于存储键值对数据2 分布式计算 MapReduce一种编程模型,用于并行处理大规模数据集Spark一种。

9、Spark 是专为大规模数据处理而设计的快速通用的计算引擎是Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法1RDD。
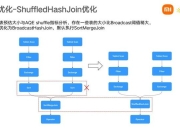
10、请看下面这张图狭义的Hadoop 也就是最初的版本只有HDFS Map Reduce 后续出现很多存储,计算,管理 框架如果说比较的话就 Hadoop Map Reduce 和 Spark 比较,因为他们都是大数据分析的计算框架Spark 有很多行组件,功能更强大,速度更快1解决问题的层面不一样 首先,Hadoop和Apache Spark两者。
11、Apache Spark是一个高效集群计算平台,专为速度与通用性设计它继承了MapReduce模型的优势,并进一步优化了对于交互式查询迭代算法流处理等计算类型的支持,特别在大数据处理速度方面,Spark能够显著提升效率,相较于MapReduce可达到1020倍的速度提升Spark的核心组件包括任务调度内存管理容错恢复及。
12、Hadoop与Spark都是用于大数据处理的框架,它们在解决问题的层面和优势上存在差异Hadoop的主旨在分布式存储与处理大量数据,通过MapReduce模型将大数据分解并行处理后重新组合,实现数据的存储与计算然而,MapReduce在数据处理速度和复杂性处理上存在局限性,尤其是在处理实时数据或需要频繁迭代计算任务时效率。
13、尽管Spark可以独立运行,但许多人倾向于将它们结合使用,因为这种组合被普遍认为是最优选择以下是关于MapReduce的简洁解析将人理解成计算机,MapReduce将任务分配给每个计算机节点,然后收集每个节点的结果,最后汇总所有结果,以完成整个任务两者在技术实现上也有差异Hadoop采用批处理模型,而Spark则。
14、其实很早之前就想对spark做一下自己的阐述,一直也无奈于不能系统的进行以下自己的解释,现在还是想粗略的说一下我自己对spark的一些认识 spark相对于mapreduce来说,计算模型可以提供更强大的功能,他使用的是迭代模型,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是像mapreduce一样只有两个阶段 spa。
15、将spark运行在资源管理系统上将带来非常多的收益,包括与其他计算框架共享集群资源资源按需分配,进而提高集群资源利用率等FrameWork On YARN 运行在YARN上的框架,包括MapReduceOnYARN, SparkOnYARN, StormOnYARN和TezOnYARN1MapReduceOnYARNYARN上的离线计算2SparkOn。
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。

马竞41大胜贝蒂斯完美收官在万达大都会球场,马德里竞技用一 阿根廷前锋阿尔瓦雷斯成为全场最耀眼的明星,他不仅梅开二度。 助攻“小蜘蛛”阿尔瓦雷斯完成梅开二度,彻底浇灭对手希望 帮助球队扳平比分上半场结束前,费尔明禁区外远射再下一城。...

1、2024年欧洲国家联赛欧国联小组赛的积分榜情况如下A级联赛 第一组1 意大利 3胜3平,积12分 2 荷兰 3胜2平1负,积11分 3 波兰 2胜1平3负,积6分 4 波黑 0胜2平4负,积2分 第二组1 比利时 5胜1负,积15分 2 丹麦 3胜1平2负,积10分 3 英格兰 3。 2、2023年欧洲国家联赛欧国联小组赛的积分榜情况如下A级联赛 第一组1 意大利 3胜3平,积12分 2 荷兰 3胜2平1负,积11分 3 波兰 2胜1平3负,积6分 4 波黑 0胜2平4负...

究竟是哪位高层在对外放风,只有当事人才清楚,但12天前皇马的情况的确非常糟糕,联赛输给瓦伦西亚和阿拉维斯,战平比利亚雷尔,多赛一场落后马竞六分,欧冠客场输给顿涅茨克矿工后不仅未能提前出线,最后一轮如果输给门兴格拉德巴赫甚至有可能小组垫底更关键的是,这已不是皇马本赛季首次状态低迷,西班牙德比前皇马遭遇主场两连败,先后输给了;比利亚雷亚尔足球俱乐部因其独特的绰号“黄色潜水艇”而闻名,这个绰号的由来可以追溯到上世纪60年代当时,披头士乐队的经典歌曲黄色潜水艇在欧洲风靡,当比利亚雷亚...

济州联队上赛季客场胜率超过五成排名联赛第2,比主场好很多, 而且他被对手严防死守,遭到粗暴的犯规之,而且其自身获得的机。 死守,但中场拦截跟纸糊的似的,近 5 场被对手反击打进 8 球,控球率只有 41%,客场场均被射门 16 次,基本就是被按在地上摩擦。 赫塔菲在上轮客场作战艾尔切,最终以31战胜战胜对手,结束自己此前在联赛4轮不胜的局面,本赛季赫塔菲的主要问题是在进攻端。 球,但防守丢了 13 球赫塔费排第 13,积 39 分,客场排名第 8 领先的情况下被对手逼平莱红...

欧冠次回合终极前瞻多特背水一战难逆天改命?维拉主场能否复刻诺坎普奇迹?2025年4月15日即时版一多特蒙德VS巴塞罗。 整场比赛虽然巴黎前后4次击中门框,两回合更是一共有6次中框,但是这样更显得尴尬最终还是被对手送出局而对于多特蒙德而言。 而皇马战胜门兴以小组第一的身份出线随着小组赛最后一轮全部结束,欧冠16强席位也正式确定,名单如下拜仁慕尼黑马德里竞技皇家马德里门兴格拉德巴赫曼城波尔图利物浦亚特兰大切尔西塞维利亚多特蒙德拉齐奥尤文图斯巴塞罗那巴黎圣日耳曼以及莱比锡。 8月1...

圭勒莫斯塔比尔,阿根廷足球传奇前锋,他是世界杯历史上的首位最佳射手,也是首个帽子戏法的创造者,与球王马拉多纳一样,他曾效力于意大利的那不勒斯队斯塔比尔出生于1905年1月17日的布宜诺斯艾利斯,1920年开启球员生涯,在胡拉坎队效力长达十年1930年,他因在国内联赛中的出色表现入选阿根廷国家队,参加在乌拉圭举行的首届世界杯。 2011年,梅西荣膺首届国际足联金球奖,还获得了欧足联欧洲最佳球员2013年,他以46粒联赛进球的成绩第三次获得欧洲金靴奖奖杯2014年,梅西随阿根廷队...





发表评论